CrowdStrike’s Response
CrowdStrike CEO George Kurtz responded promptly, assuring users that the issue had been identified and a fix had been made available. “This is not a security incident or cyberattack,” Kurtz stated in a post on X. “The issue has been identified, isolated, and a fix has been deployed. We refer customers to the support portal for the latest updates and will continue to provide complete and continuous updates on our website.”
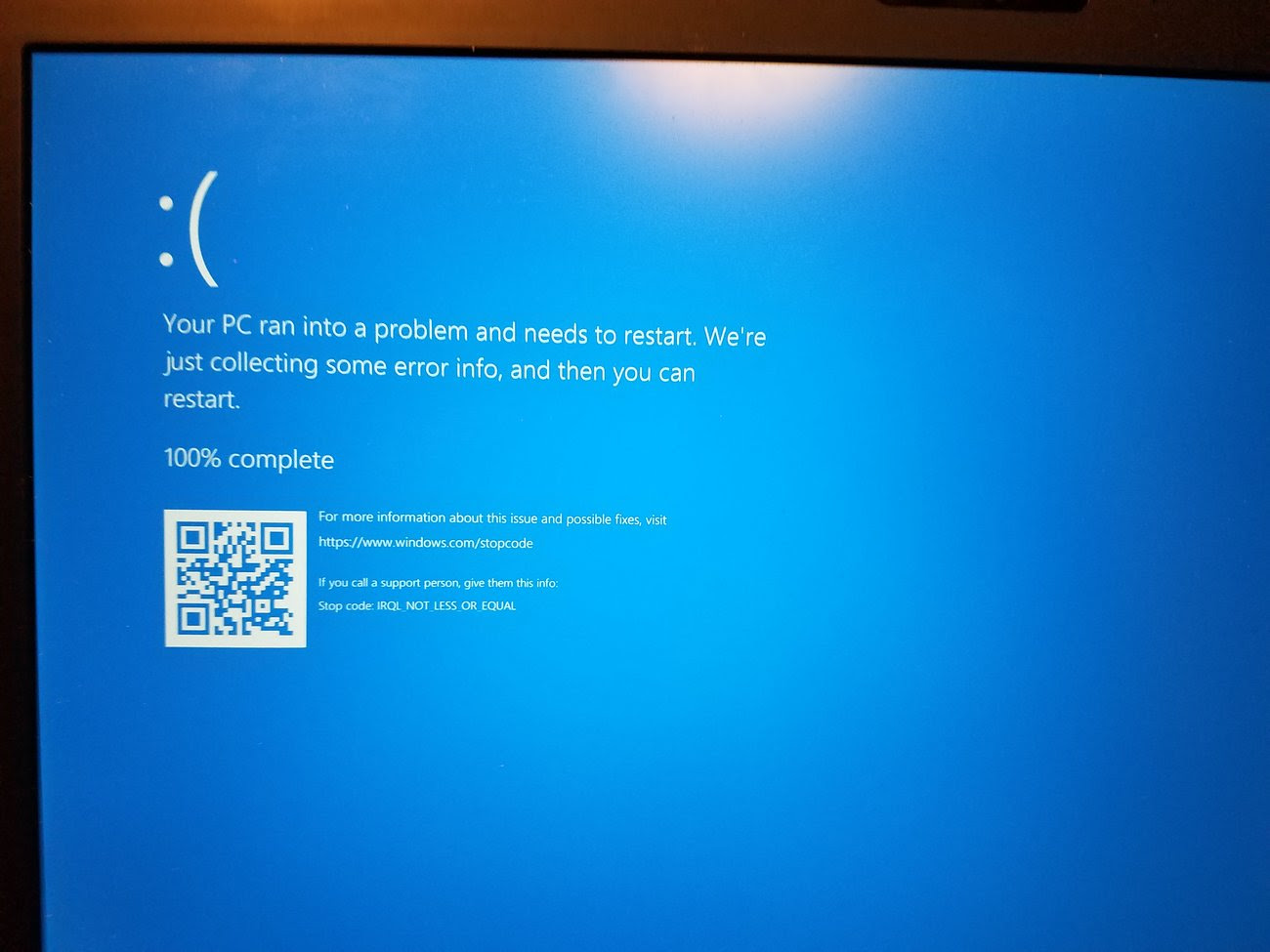
Despite the fix, recovery from the outages may take days. Grossman pointed out a critical challenge: “It turns out that because the endpoints have crashed – the Blue Screen of Death – they cannot be updated remotely and this problem must be solved manually, endpoint by endpoint.”
The Fragility of Monocultural Supply Chains
This event has highlighted the inherent fragility of relying heavily on a few large technology vendors. Omkhar Arasaratnam, general manager of the Open Source Security Foundation (OpenSSF), commented on this vulnerability: “Good system engineering tells us that changes in these systems should be rolled out gradually, observing the impact in small tranches vs. all at once. More diverse ecosystems can tolerate rapid change as they’re resilient to systemic issues.”
Relying on a monocultural supply chain means that when a single point of failure occurs, such as the bad update from CrowdStrike, the consequences can be catastrophic. The dependency on a single type of system or software creates a scenario where a failure affects a vast number of systems simultaneously, leading to widespread disruptions.
The current incident is a prime example of the risks posed by monocultural dependencies. Major airlines experienced flight delays and cancellations, emergency services like 911 were disrupted, and healthcare facilities faced operational challenges—all due to a single software update gone wrong. This concentration of risk in a monocultural system underscores the need for diversification and resilience in our technological infrastructures.
Arasaratnam’s point about gradual rollouts is crucial. By implementing changes in smaller, controlled phases, companies can monitor the effects and mitigate potential issues before they escalate. This approach reduces the risk of widespread failure and allows for quicker responses to any emerging problems.
Marcus Merrell, principal test strategist at Sauce Labs, echoed this sentiment, stressing the importance of gradual updates: “Everything is software and software is everything – it’s more interconnected and interdependent than ever. If the software update release affects not just your users but your users’ users, you must slow-roll the release over a period of hours or days, rather than risk crippling the entire planet with one large update.”
Merrell’s insight highlights the complexity and interdependence of modern software ecosystems. A single update can have cascading effects across multiple layers of users and systems. The principle of gradual rollouts and meticulous monitoring becomes even more critical in this context, ensuring that any potential issues are caught early and addressed promptly.
Lessons and Future Precautions
This incident also underscores the need for rigorous software testing and risk assessment. A recent survey from Sauce Labs revealed that 67% of respondents had pushed code to production before testing it, with 28% admitting to doing so regularly. Merrell emphasized the importance of assessing risks: “The equation is simple: what is the risk of not shipping a code versus the risk of shutting down the world?”
Dr. Dawkins Brown, the executive chairman of Dawgen Global, offered his perspective on the incident: “This outage is a stark reminder of the critical need for robust cybersecurity strategies and diligent risk management. Businesses must prioritize comprehensive testing and gradual implementation of updates to safeguard their operations and maintain trust in their systems.”
In conclusion, while the immediate crisis caused by the CrowdStrike update is being addressed, the event serves as a wake-up call for businesses worldwide. It highlights the necessity of adopting more resilient and diverse technological ecosystems, implementing stringent testing protocols, and approaching updates with caution to prevent similar disruptions in the future. By learning from this incident, companies can better prepare for and mitigate the impacts of future software failures, ensuring smoother and more reliable operations.
 On the morning of July 19,2024, a significant number of major systems experienced widespread outages due to a problematic update from CrowdStrike, an endpoint protection system. The update, which was intended to enhance security, inadvertently caused Windows machines running the updated software to crash. This incident underscores the vulnerabilities inherent in our heavily interconnected digital world and highlights the critical importance of robust cybersecurity measures.
On the morning of July 19,2024, a significant number of major systems experienced widespread outages due to a problematic update from CrowdStrike, an endpoint protection system. The update, which was intended to enhance security, inadvertently caused Windows machines running the updated software to crash. This incident underscores the vulnerabilities inherent in our heavily interconnected digital world and highlights the critical importance of robust cybersecurity measures.
